很多(虚拟的)墨水已经洒在这个博客上关于自动化测试(不,真的).这篇文章是关于不同的自动化测试工具以及如何使用它们来交付更好、更高质量的web应用程序的系列文章中的另一篇。
在这里,我们将重点关注特定于的工具和服务'视觉回归测试——特别是应用程序前端的跨浏览器可视化测试。
什么?
通过可视化回归测试,我们指的是专门应用于应用程序外观的回归测试,这些外观可能会随着浏览器或时间的推移而发生变化,而不是功能行为。
为什么?
测试web应用最常见的起点之一是打开一个给定的浏览器,在测试环境中导航到应用,并注意外观上的任何差异(“哦,看,登录按钮颠倒了。是谁干的!?”)。

关于如何加强代码质量的一个辛辣的观点——我们不会讲到这里。
可视化回归测试的优势在于,您是在一组非常人性化的条件下测试应用程序的(应用程序在最终用户眼中是怎样的,以及它是怎样的应该看)。缺点是这样做通常是耗时和乏味的。但这就是我们有自动化的原因!

如何我们的汉堡呈现在Chrome vs如何它呈现在IE 11…
如何?
一位智者曾经说过,“在软件自动化中,没有这样的方法调用‘if != ugly, return true’”。
在大多数情况下,这种说法是正确的。在给定的浏览器支持矩阵下,完全自动化地测试web应用程序的外观,对于软件自动化问题,真的没有什么“银弹”。至少没有一些警告。
这样做的方法和工具可能与以下至少一种冲突:
- 他们很昂贵(在时间、金钱或两者方面)
- 他们很脆弱(测试会产生假阴性,可能不可靠)
- 它们是有限的(只涵盖受支持的浏览器的一个子集)

当然,您可以支持精巧的工具。只要记住总成本。
工具
我们将展示如何快速设置一组工具使用WebdriverIO,一些简单的JavaScript测试代码和可视化回归服务模块来创建应用程序前端的快照,并根据其外观执行测试。
设置
假设你已经有了一个web应用程序,可以在你选择的环境中测试(希望不是在生产环境中),并且你熟悉NodeJS,让我们开始编写我们的测试解决方案:

这个梗太老了,我都不能…
1.在命令行中,创建一个新的项目目录,并按以下顺序执行:
- ' npm init '(遵循初始化提示-可以使用默认值并稍后更新)
- 安装-保存-dev webdriverio
- ' npm install -save-dev wdio-visual-regression-service '
- npm install -save-dev chai
2.一旦完成模块的安装,就需要配置WebdriverIO实例。您可以手动创建文件“wdio.conf.js”并将其放置在项目根目录中(请参阅WebdriverIO开发者指南关于在配置文件中包含什么),或者您可以使用wdio自动化配置脚本。
3.为了快速配置你的工具,在你的项目根目录下运行' npm run wdio '来启动自动配置脚本。在配置过程中,请确保选择以下内容(如果手动设置,则将其包含在wdio.conf.js文件中):
- 在框架下,确保启用摩卡(我们将使用它来处理断言之类的事情)
- 在services下,确保启用以下功能:
- visual-regression
- Browserstack(我们将利用Browserstack处理所有来自WebdriverIO的浏览器请求)
注意,在这种情况下,我们不会安装selenium独立服务或任何本地测试二进制文件Chromedriver.这个练习的目的是快速地将一些占用空间非常小的工具打包在一起,可以处理任何给定web应用程序前端的高级回归测试。
完成配置脚本后,您的项目中应该有一个wdio.conf.js文件,该文件已配置为使用WebdriverIO和可视化回归服务。
接下来,我们需要创建一个测试。
编写测试
首先,在项目的主源代码中创建一个名为tests/的目录。在该目录中,创建一个名为首页.js的文件。
设置文件内容如下:
description ('home page', () => {beforeEach(function () {browser.url('/');});it('应该看起来像预期的那样',()=> {browser.checkElement('#header');});});
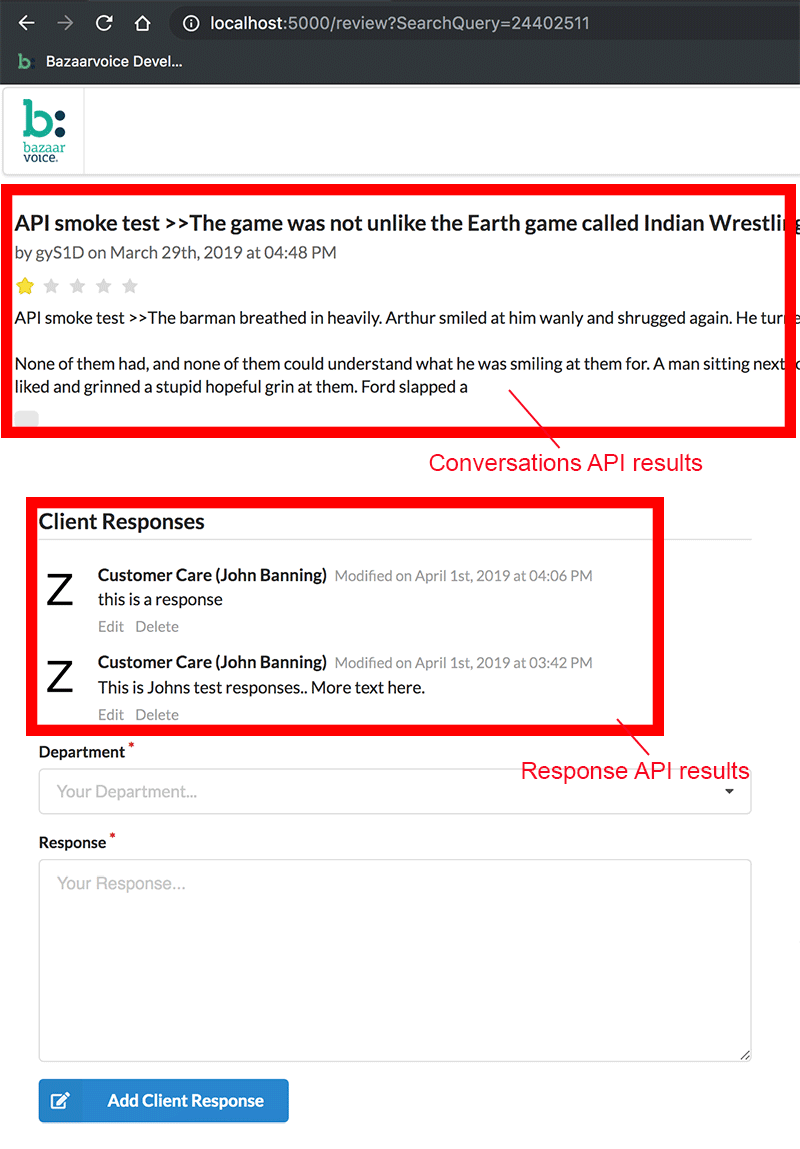
就是这样。在单个测试函数中,我们调用了来自可视化回归服务的方法“checkElement()”。在我们的代码中,我们提供了ID, ' header '作为参数,但你应该用你想检查的页面上容器元素的ID或CSS选择器替换这个参数。
当执行时,WebdriverIO将打开它为我们的web应用程序提供的根URL路径,然后将执行它的检查元素比较操作。这将生成应用程序的一系列参考屏幕截图。然后回归服务将在每个浏览器中生成应用程序的屏幕截图,并在这些屏幕和参考图像之间提供一个增量。
更复杂的测试:
在你希望执行可视化回归测试之前,你可能需要明确你的web应用程序的一部分。还可能需要执行checkElement ()函数多次使用多个参数,以这种方式全面审查应用程序前端的外观和感觉。
幸运的是,由于我们只是通过WebdriverIO继承了可视化回归服务的操作,我们可以在测试中结合基于webriverio的方法调用来操作和验证我们的应用程序:
description ('home page', () => {beforeEach(function () {browser.url('/');});it('应该看起来像预期的那样',()=> {browser.waitForVisible('#header');browser.checkElement(“#头”);});它('应该看起来正常后,我点击按钮,()=> {browser.waitForVisible('.big_button');browser.click(“.big_button”);browser.waitForVisible(“# main_content”);browser.checkElement(“# main_content”);}); it('should have a footer that looks normal too, () => { browser.scroll('#footer'); browser.checkElement('#footer'); }); });
广泛关注与狭隘关注:
可能会增加这样的视觉测试的脆弱性的几个因素之一是试图解释视觉元素中的微小变化。这是一件很难同时兼顾的事情。
尝试检查一个大型且填充量很大的容器(例如body标签)的内容很可能包含跨浏览器的许多可能的变体,以至于您的测试总是会抛出异常。相反,试图将测试的重点缩小到一些非常边缘的东西(例如,选择单个按钮的单个实例)可能永远不会被前端开发人员实现的代码所触及,因此,你可能会错过应用程序UI的关键更改。

这太多了,不能一次测试。
可视化回归服务的神奇之处在于,它允许你针对给定网页的特定区域或应用程序中的路径进行测试——基于Webdriver可以解析的web选择器。

这太少了…
理想情况下,你应该选择一个内容范围不太大也不太小,而是介于两者之间的网页选择器。一个专注于比较包含3-4个小部件的特定div标签的内容的测试,可能比一个专注于单个按钮的选择器或包含30个小部件或各种web元素的div的测试更有价值。
或者,你的一些应用前端可能是由模板或脚手架生成的,这些模板或脚手架从未收到更新,并且与你的团队频繁更改的代码隔离开来。在这种情况下,围绕这些方面编组测试可能会导致浪费大量时间。

但这是对的!
相应地选择你关注的领域。
回到手头的配置:
在运行测试之前,让我们对配置文件进行一些更新,以确保我们已经准备好运行初始的主页验证脚本。
首先,我们需要添加一些帮助函数来方便截图管理。在配置文件的顶部,添加以下代码块:
Var path = require('path');var VisualRegressionCompare = require('wdio-visual-regression-service/compare');函数getScreenshotName(basePath){返回函数(上下文){var类型= context.type;var testName = context.test.title;var browserVersion = parseInt(context.browser. var。版本,10);var browserName = context.browser.name;var browserViewport = context.meta.viewport;var browserWidth = browserViewport.width;var browserHeight = browserViewport.height;返回路径。join(basePath, `${testName}_${browserName}_v${browserVersion}_${browserWidth}x${browserHeight}.png`); }; }
这个函数将被用来为我们在测试期间将要拍摄的各种屏幕截图构建路径。
如前所述,我们在这个例子中利用Browserstack来最小化我们需要交付的代码量(假设我们希望将这个项目作为Jenkins任务中的资源),同时允许我们在可以测试的浏览器中具有更大的灵活性。要做到这一点,我们需要确保配置文件中的一些更改到位。
注意,如果您正在使用不同的浏览器供应服务(SauceLabs, Webdriver的网格实现),参见WebdriverIO的在线文档对于如何设置您的wdio配置为您各自的服务在这里)。
打开你的wdio.conf.js文件,确保这段代码是存在的:
用户:process.env。BSTACK_USERNAME, key: process.env。BSTACK_KEY,主机:'hub.browserstack.com',端口:80,
这允许我们通过命令行将浏览器堆栈身份验证信息传递到wdio脚本中。
接下来,让我们设置希望使用哪些浏览器进行测试。这也是在我们的wdio配置文件' capabilities '对象下完成的。这里有一个例子:
能力:[{browserName: 'chrome', os: 'Windows',项目:'My project - chrome', 'browserstack. '本地':false,}, {browserName: 'firefox',操作系统:'Windows',项目:'我的项目- firefox', '浏览器堆栈。local': false,}, {browserName: 'internet explorer', browser_version: 11, project: 'My project - IE 11', 'browserstack. local': false,}, {browserName: 'internet explorer', browser_version: 11Local ': false,},],
屏风应该放在哪里:
当我们在这里时,请确保您已经设置了配置文件,专门指向您希望将屏幕截图复制到的位置。可视化回归服务将想知道它将生成和管理的4种类型的截图的路径:

是的,太多屏幕了
参考文献:此目录将包含视觉回归服务在初始运行时生成的参考图像。这将是我们后续屏幕截图将与之进行比较的内容。
屏幕:此目录将包含测试生成的每种浏览器类型/视图的屏幕截图。
错误:如果给定的测试失败,应用程序将在故障点捕获图像并存储在这里。
差别:如果视觉回归服务在浏览器执行的元素和参考图像之间执行了一个给定的比较,结果导致差异,则将捕获并存储在这里的差异的“热图”图像。将此目录的内容视为您的测试异常。
事情变得模糊:

法兹,不是福兹
最后,在开始测试之前,我们需要在wdio.conf.js文件中启用可视化回归服务实例。这是通过向配置文件中添加一段代码来完成的,该代码块指示服务如何运行。下面是一个摘自WebdriverIO开发者指南的代码块示例:
visualRegression:{比较:新的VisualRegressionCompare。LocalCompare({referenceName: getScreenshotName(path.join(process.cwd(), '截图/参考')),screenshotName: getScreenshotName(path.join(process.cwd(), '截图/屏幕')),diffName: getScreenshotName(path.join(process.cwd(), '截图/屏幕')),misMatchTolerance: 0.20,}), viewportChangePause: 300, viewports:[{宽度:320,高度:480},{宽度:480,高度:320},{宽度:1024,高度:768}],朝向:['portrait'],},
将此代码块放在文件中的“services”对象中,并根据需要编辑它。请注意以下属性,并根据您的测试需求进行调整:
“视窗”:这是一个JSON对象,提供用于测试应用程序的宽度/高度对。如果你的应用程序有特定的响应式设计限制,这是非常方便的。对于每一对,测试将在每个浏览器上执行——为每一组尺寸调整浏览器的大小。
“方向”:这允许您配置测试以使用纵向和/或横向视图(如果您碰巧在移动浏览器中测试的话)执行(默认方向是纵向)。
“viewportChangePause”:在指示服务更改视口大小的每个点上,该值以毫秒为单位暂停测试。您可能需要根据应用程序在不同浏览器中的性能来限制这一点。
“mismatchTolerance”:可以说是最重要的设定。这个浮点值定义了“模糊因子”,服务将使用它来确定参考和屏幕截图之间的视觉差异应该在什么时候失效。默认值0.10表示,如果给定的屏幕截图与参考像素的差异为10%或更多,则会生成一个差异。数值越大,容忍度就越大。
完成配置文件的修改后,让我们执行一个测试。
运行测试:
如果您的配置文件被设置为指向项目中测试文件所在位置的根,则编辑您的包。Json文件,并在文件的脚本部分修改“test”描述符。
设置如下:
”。/ node_modules /。bin / wdio / wdio.desktop.conf.js '
要从命令行运行测试,请执行以下操作:
' BSTACK_USERNAME= BSTACK_KEY= npm run test - - baseurl = '
现在,坐好,等着测试结果出来。如果这是您第一次执行这些测试,那么在试图通过Browserstack捕获各种浏览器的初始引用时,可视化回归服务可能会失败。您可能需要在第一次运行时增加测试的全局超时,或者在这种情况下只需重新运行测试。
审核结果:
如果您习惯了标准的JUnit或jest风格的测试执行输出,那么这里的测试输出就不一定类似。
如果在测试过程中出现功能错误(您试图检查的对象在屏幕上不可用),将生成一个标准的基于webdriver的异常。然而,除此之外,您的测试将通过—即使在视觉上检测到差异。
但是,请检查我们前面提到的屏幕截图文件夹结构。注意已经生成的文件的数量。打开其中的几个,看看在通过Browserstack测试时,通过ie11和Chrome捕获了什么。
请注意,文件后面附加了名称,用于描述它们对应的浏览器和视口尺寸。

来自特定浏览器的屏幕截图示例
注意是否生成了“Diff”目录。如果是,检查一下它的内容。这些是您的测试结果——具体地说,是您的测试失败。

一个不同的图像的例子
对于我们在这里设置的基本工具集,还有许多其他选项可供探索。然而,我们将在这里暂停,并沉浸在能够使用5-10行代码执行这种级别的浏览器测试的美妙之中。
还有吗?
这篇文章实际上只是触及了使用一组可视化回归测试工具所能做的事情的表面。使用这些工具还有很多选择,比如启用移动测试,改进错误处理,并将其与构建工具和服务相匹配。
我们希望在以后的文章中更深入地讨论这些主题。现在,如果您正在寻找额外的阅读材料,请随意查看其他一些关于可视化回归测试的相关文章在这里,在这里而且在这里.